Меню:
This article doesn't pretend to be detailed description on how to setup Emacs to be complete development environment. I just tried to provide a small description on "How to setup CEDET to work with C, C++ & Java", although most of this description will be also applicable for other languages, supported by CEDET1.
What is CEDET?
The CEDET package is a collection of libraries, that implement different commands, but all of them have common goal — provide functionality for work with source code written in different programming languages (please, take into account that not all of these packages are included into CEDET bundled with GNU Emacs):
- Semantic is a base for construction of syntactic analyzers for different programming languages. It provides common representation of information extracted from code. Using this information, CEDET & other packages, such as JDEE and ECB, can implement functionality, required for modern development environment — name completion, code navigation, etc.;
- SemanticDB is included into Semantic, and implements different storage modules, that store information, needed for names completion, source code navigation, etc. Syntactic information may be saved between Emacs sessions, so this reduces need for re-parsing of source code that wasn't modified since last parse;
- Senator implements navigation in source code using information extracted by Semantic;
- Srecode is a package for source code generation using syntactic information (including information, extracted by Semantic);
- EDE implements a set of extensions to work with projects — user can control list of the targets to build, build the project, etc. Besides this, using the notion of the project, you can have more precise control over Semantic's operations — name completions, navigation, etc.;
- Speedbar is used to display information about current buffer using different sources of information — Semantic, some specialized information providers (for texinfo & HTML, for example).
- Eieio is a library, that implements CLOS-like (Common Lisp Object System) infrastructure for Emacs Lisp;
- Cogre is a library for generation of UML-like diagrams in Emacs buffer, with basic integration with Semantic.
CEDET's versions
We need to understand that there are several versions of CEDET, that differ from each other by installation & customization methods:
- standalone versions of CEDET up to version 1.1 (including) — these versions are
available for downloading from project's site. This version uses "old" layout for
source code & activation method that isn't compatible with version included into GNU
Emacs. In this version, files with source code often had "long names", like
semanticdb.el, orsemantic-gcc.el, and this made them incompatible with some of operating systems supported by GNU Emacs; - standalone CEDET versions after 1.1 release — they use "new" directory layout and the
same activation method as in GNU Emacs, but these versions usually have more
functionality & include some additional packages, like Senator. In this version,
layout of source code was changed to match GNU Emacs, so some files was renamed: for
example,
semanticdb.elwas renamed tosemantic/db.el, andsemantic-gcc.elbecamesemantic/bovine/gcc.el, etc. - version that is bundled with GNU Emacs (starting with GNU Emacs 23.2) — some packages aren't included into this version, and code could be "outdated", comparing with current standalone versions of CEDET.
This article describes new version of CEDET, including version bundled with GNU Emacs. If you want to use standalone release 1.1, or earlier, then you need to read previous version of this article.
Installation of standalone CEDET's version
Right now (October, 2012) there is no released version of CEDET with "new" activation method, so you need to take current snapshot, or get version from repository. Unpack source code, if this is necessary, change to directory & perform following command that will compile everything:
make clean-all && make
Customization
If you're using standalone CEDET's version, then you need to load it with following command:
(load-file "~/emacs/cedet-bzr/cedet-devel-load.el")
But if you're using CEDET bundled with GNU Emacs, then everything will be already loaded on start.
Semantic's customization
All standalone versions until release 1.1 (including) had activation method that was
different from method for CEDET bundled into GNU Emacs. In new versions activation of
package is performed by adding of symbols for selected sub-modes into special list, and
then activating semantic-mode. While in the "old" versions, functionality was activated
by calling one of the functions, each of them activated some specific set of features. So
in the "new" version, it's enough to do following:
(semantic-mode 1)
And set of enabled features will depend on what will be put into list
semantic-default-submodes, that can contain following symbols (it's better to populate
this list before enabling semantic-mode):
global-semanticdb-minor-mode- enables global support for Semanticdb;
global-semantic-mru-bookmark-mode- enables automatic bookmarking of tags that you
edited, so you can return to them later with the
semantic-mrub-switch-tagscommand; global-cedet-m3-minor-mode- activates CEDET's context menu that is bound to right mouse button;
global-semantic-highlight-func-mode- activates highlighting of first line for current tag (function, class, etc.);
global-semantic-stickyfunc-mode- activates mode when name of current tag will be shown in top line of buffer;
global-semantic-decoration-mode- activates use of separate styles for tags decoration
(depending on tag's class). These styles are defined in the
semantic-decoration-styleslist; global-semantic-idle-local-symbol-highlight-mode- activates highlighting of local names that are the same as name of tag under cursor;
global-semantic-idle-scheduler-mode- activates automatic parsing of source code in the idle time;
global-semantic-idle-completions-mode- activates displaying of possible name
completions in the idle time. Requires that
global-semantic-idle-scheduler-modewas enabled; global-semantic-idle-summary-mode- activates displaying of information about current
tag in the idle time. Requires that
global-semantic-idle-scheduler-modewas enabled.
Following sub-modes are usually useful when you develop and/or debug CEDET:
global-semantic-show-unmatched-syntax-mode- shows which elements weren't processed by current parser's rules;
global-semantic-show-parser-state-mode- shows current parser state in the modeline;
global-semantic-highlight-edits-mode- shows changes in the text that weren't processed by incremental parser yet.
This approach allows to make Semantic's customization more flexible, as user can switch on
only necessary features. You can also use functions with the same names to enable/disable
corresponding sub-modes for current Emacs session. And you can also enable/disable these
modes on the per-buffer basis (usually this is done from hook): names of corresponding
variables you can find in description of global-semantic-* functions.
To enable more advanced functionality for name completion, etc., you can load the
semantic/ia with following command:
(require 'semantic/ia)
After loading of this package, you'll get access to commands, described below.
System header files
To normal work with system-wide libraries, Semantic should has access to system include files, that contain information about functions & data types, implemented by these libraries.
If you're using GCC for programming in C & C++, then Semantic can automatically find
directory, where system include files are stored. Just load semantic/bovine/gcc package
with following command:
(require 'semantic/bovine/gcc)
You can also explicitly specify additional directories for searching of include files (and
these directories also could be different for specific modes). To add some directory to
list of system include paths, you can use the semantic-add-system-include command — it
accepts two parameters: string with path to include files, and symbol, representing name
of major mode, for which this path will be used. For example, to add Boost header files
for C++ mode, you need to add following code:
(semantic-add-system-include "~/exp/include/boost_1_37" 'c++-mode)
Although I want to say, that customization for Boost support is more complex, and requires to specify where Semantic can find files with constant's definitions, etc.
Semantic's work optimization
To optimize work with tags, you can use several techniques:
- limit search by using an EDE project, as described below;
- explicitly specify a list of root directories for your projects, so Semantic will use limited number of databases with syntactic information;
- explicitly generate tags databases for often used directories (
/usr/include,/usr/local/include, etc.). You can use commandssemanticdb-create-ebrowse-databaseorsemanticdb-create-cscope-database; - limit search by customization of the
semanticdb-find-default-throttlevariable for concrete modes — for example, don't use information from system include files, by removingsystemsymbol from list of objects to search forc-mode:
(setq-mode-local c-mode semanticdb-find-default-throttle
'(project unloaded system recursive))
Semantic extracts syntactic information when Emacs is idle. You can customize the
semantic-idle-scheduler-idle-time variable to specify idle time (in seconds), if you don't
want to use default value (1 second).
Integration with imenu
The Semantic package can be integrated with the imenu package. This lead to creation of a menu with a list of functions, variables, and other tags. To enable this feature you need to add following code into your initialization file:
(defun my-semantic-hook () (imenu-add-to-menubar "TAGS")) (add-hook 'semantic-init-hooks 'my-semantic-hook)
Customization of Semanticdb
To enable Semanticdb you need to add the global-semanticdb-minor-mode symbol into the
semantic-default-submodes list. And you can specify some customization variables to
control behaviour of Semanticdb — for example, where to save data, etc. These variables
could be set via semanticdb customization group.
Semanticdb can also use databases generated by external utilities: gtags (from
GNU Global), exubertant ctags, ebrowse & cscope. To activate this functionality you can
use following code (please, note that these commands may fail if you have no utilities
installed, or have an incorrect versions of them — that's why they a wrapped into when):
;; if you want to enable support for gnu global (when (cedet-gnu-global-version-check t) (semanticdb-enable-gnu-global-databases 'c-mode) (semanticdb-enable-gnu-global-databases 'c++-mode)) ;; enable ctags for some languages: ;; Unix Shell, Perl, Pascal, Tcl, Fortran, Asm (when (cedet-ectag-version-check t) (semantic-load-enable-primary-exuberent-ctags-support))
EDE's customization
If you plan to use projects, then you need to enable corresponding mode, implemented by the EDE package:
(global-ede-mode t)
There are several types of projects supported by EDE, and I want to describe here only some of them.
Using EDE for C & C++ projects
For correct work of Semantic with С & C++ code it's recommended to use the EDE package (it
allows to work with projects, etc.). For these languages, EDE package defines special
project type: ede-cpp-root-project, that provides additional information to Semantic, and
this information will be used to analyze source code of your project.
To define a project, you need to add following code:
(ede-cpp-root-project "Test" :name "Test Project" :file "~/work/project/CMakeLists.txt" :include-path '("/" "/Common" "/Interfaces" "/Libs" ) :system-include-path '("~/exp/include") :spp-table '(("isUnix" . "") ("BOOST_TEST_DYN_LINK" . "")))
For the :file parameter you can use any file at root directory of your project. This file
isn't parsed — it's used only as an anchor to search all other files in project.
To search include files, Semantic uses directories from two lists, that could be specified
for project. The :system-include-path parameter is used to specify list of full paths
where lookup for "system" include files will be performed. Another parameter —
:include-path specifies the list of directories, that will be used to search of "local"
include files (if names are starting with /, this means, that path is specified relative
to project's root directory). Instead of specifying paths as lists, you can also provide
function, that will perform search of include files in your project. You can read about
it in the EDE manual.
Another parameter, that could be specified in project's declaration is a list of
definitions, that will be used during code preprocessing. The :spp-table parameter allows
to specify list of pairs, consisting from symbol's name & value, defined for given symbol.
In our example above, we defined two symbols —
isUnix and BOOST_TEST_DYN_LINK, that will
be passed to preprocessor, and this will allow to perform proper parsing of the code.
User, if required, can redefine some variables for files inside project. This could be
done by specifying the :local-variables parameter with value that is a list of pairs in
form symbol name/value, and these values will be set for files in project.
Preprocessing of source code
More information about definitions for C/C++ preprocessor you can find in documentation
for the semantic-lex-c-preprocessor-symbol-map variable. You can obtain list of
preprocessor symbols, defined for file with source code, by using the
semantic-lex-spp-describe command. And then use these results to set :spp-table parameter
or semantic-lex-c-preprocessor-symbol-map variable.
Many libraries store all macro definitions in one or more include files, so you can use
these definitions as-is. To do this you need to specify these files in the
semantic-lex-c-preprocessor-symbol-file variable, and when CEDET will perform analysis,
then values from these files will be used. By default, this variable has only one value
— file with definitions for C++ standard library, but you can add more data there. As
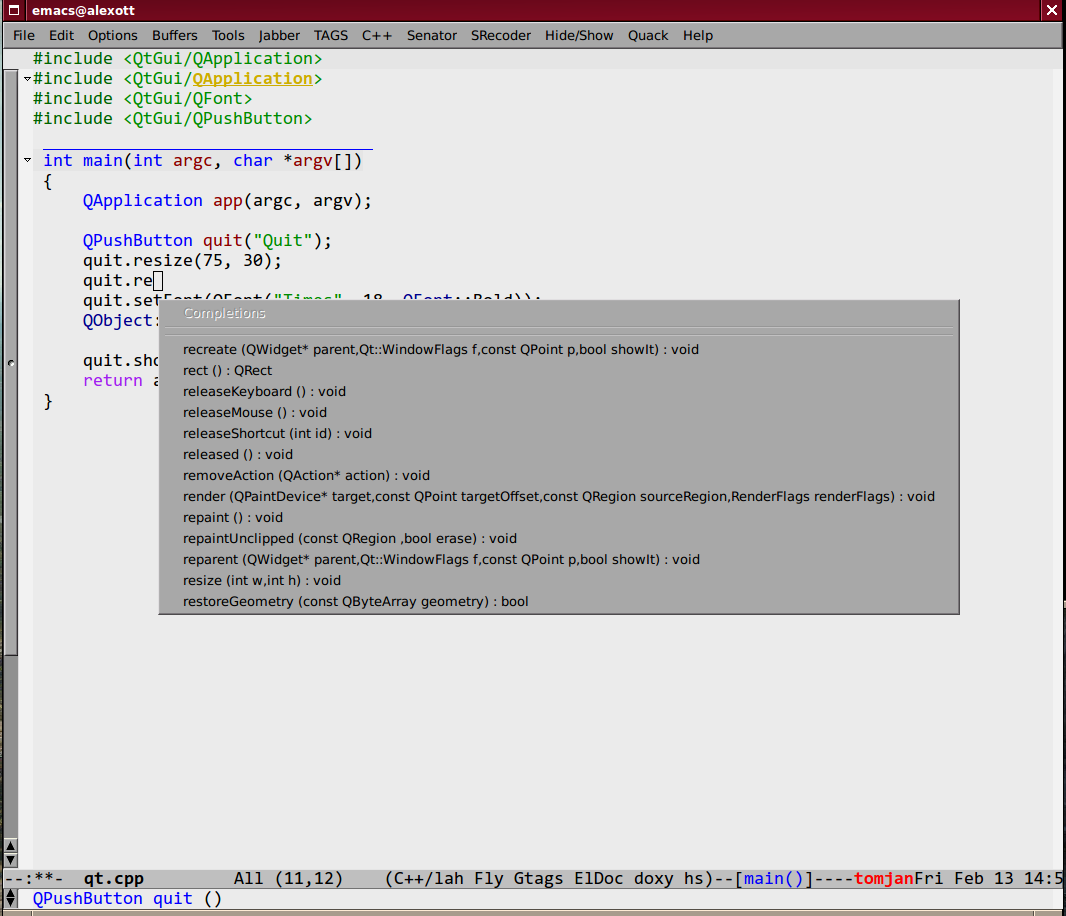
example, I want to show CEDET's configuration for work with Qt4:
(setq qt4-base-dir "/usr/include/qt4") (semantic-add-system-include qt4-base-dir 'c++-mode) (add-to-list 'auto-mode-alist (cons qt4-base-dir 'c++-mode)) (add-to-list 'semantic-lex-c-preprocessor-symbol-file (concat qt4-base-dir "/Qt/qconfig.h")) (add-to-list 'semantic-lex-c-preprocessor-symbol-file (concat qt4-base-dir "/Qt/qconfig-dist.h")) (add-to-list 'semantic-lex-c-preprocessor-symbol-file (concat qt4-base-dir "/Qt/qglobal.h"))
After you'll add these lines to initialization file, you should be able to use names completion for classes, defined in Qt4 library. Example you can see on the picture below:
Using EDE for Java projects
Semantic includes a parser for source code written in Java, so name completion for source
code always worked, and the main problem was to get name completions for classes from JDK,
or other libraries that are used in project. For compiled code, Semanticdb can get
information about name by using javap on the list libraries in the CLASSPATH. To make it
working, you need to load the semantic/db-javap package:
(require 'semantic/db-javap)
The path to the JDK's main library (rt.jar on Linux & Windows, and classes.jar on Mac OS
X) is usually detected automatically by the cedet-java-find-jdk-core-jar function,
although you can change its behaviour by setting JAVA_HOME environment variables, or some
other parameters.
If you're using Maven to build your projects, then CLASSPATH will be calculating
automatically by running Maven in the root of your project (also for multi-module
projects). And it isn't necessary to specify project's root manually — EDE will find it
automatically by searching for the pom.xml file. I need to mention that first call to
name completion functions could be relatively slow — EDE should run Maven and collect
information about libraries that are used in the project. But after first run, this
information is cached, and next completions will be performed faster.
If you aren't using Maven, then you can either specify all used libraries in the
semanticdb-javap-classpath variable, or use the ede-java-root-project class, that is
similar to ede-cpp-root-project that was described above. To use this type of project,
you need to add something like to you initialization file:
(ede-java-root-project "TestProject" :file "~/work/TestProject/build.xml" :srcroot '("src" "test") :localclasspath '("/relative/path.jar") :classpath '("/absolute/path.jar"))
As for C/C++, you need to specify name of the project, point to existing file at the project's root directory, and some additional options:
:srcroot- list of directories with source code. Directory names are specified
relatively of project's root (in this example this is
src&test); :classpath- list of absolute file names for used libraries;
:localclasspath- list of file names for used libraries, relative to project's root.
When Semantic finds such project, it can use provided information for name completion.
Work with Semantic
From user's point of view, Semantic provides several major features — names completions,
retrieving information about tags (variables, functions, etc.), and navigation in source
code. Some of these features are implemented by semantic/ia package, while other are
implemented by Senator, and Semantic's kernel.
Some of commands have no standard key bindings, so it's better to select key bindings, that are comfortable to you, and bind commands to them, like this (only for standalone CEDET):
(defun my-cedet-hook () (local-set-key [(control return)] 'semantic-ia-complete-symbol) (local-set-key "\C-c?" 'semantic-ia-complete-symbol-menu) (local-set-key "\C-c>" 'semantic-complete-analyze-inline) (local-set-key "\C-cp" 'semantic-analyze-proto-impl-toggle)) (add-hook 'c-mode-common-hook 'my-cedet-hook)
I want to mention, that Semantic's development is pretty active, and if something doesn't work, or works wrong, then please, send examples of code to the cedet-devel mailing list — the CEDET's authors usually answers pretty fast.
Names completion
Text completion for names of functions, variables & classes is pretty often used feature
when you work with source code2. There are two packages inside Semantic that implement
this functionality —
semantic/ia and Senator (it doesn't included into GNU Emacs). You
need to take into account, that in the new versions it's recommended to use Semantic only
as source of information, and perform names completion using other packages, such as
auto-complete. You see example below.
Commands, implemented by semantic/ia use the semantic-analyze-possible-completions
function to create a list of all possible names completion, and this function takes into
account many parameters (plus it can be augmented by user's code to provide more precise
list of names). At the same time, commands from Senator package use simpler methods to
create a list of all possibles completions (usually they use information only about
definitions in the current file), and this sometime lead to wrong names completion.
If you execute the semantic-ia-complete-symbol command when you're typing code, then this
will lead to completion of corresponding name — name of function, variable, or class
member, depending on the current context. If there are several possible variants, then
this name will be completed to most common part, and if you'll call this command second
time, then buffer with all possible completions will be shown. User can also use the
semantic-ia-complete-symbol-menu command — it also performs analysis of current context,
but will display list of possible completions as a graphical menu, from which the required
name should be selected3. Besides this, there is semantic-ia-complete-tip command, that
displays list of possible completions as tooltip.
As was mentioned above, the Senator package, also provides commands for names completion.
It work very fast, but with less precision (as they use few parameters during computation
of variants for completions). The senator-complete-symbol command (C-c , TAB) completes
name for current tag, and insert first found completion as result. If it inserts wrong
name, then you can insert second name from completion list by repeating this command, and
so on. If there are a lot of the possible variants, or you want to see full list of
functions and variables for some class, then it's better to use the
senator-completion-menu-popup command (C-c , SPC) — it displays list of all possible
completions as a graphical menu.
Besides these commands, user can use special mode (only for some languages) —
semantic-idle-completions-mode (or enable it globally by adding
global-semantic-idle-completions-mode symbol into semantic-default-submodes list) — in
this mode names completions are shown automatically if user stops its work for a some time
(idle time). By default, only first possible completion is shown, and user can use the
TAB key to navigate through list of possible completions.
For C-like languages, user can use the semantic-complete-self-insert command, bound to the
. and/or > keys, as this shown below:
(defun my-c-mode-cedet-hook () (local-set-key "." 'semantic-complete-self-insert) (local-set-key ">" 'semantic-complete-self-insert)) (add-hook 'c-mode-common-hook 'my-c-mode-cedet-hook)
Evaluation of this code will lead to execution of the semantic-complete-self-insert
command when user will press . or > after variables, that are instances of some data
structure, and displaying a list of possible completions for given class or structure.
If you're programming in C & C++, then you can also get name completions using information
from Clang (versions 2.9 & above). To do this, you need to load the semantic/bovine/clang
package, and call the semantic-clang-activate function. After that, Semantic will start
to call Clang, and use its code analyzer to calculate list of possible names completions.
Names completion with auto-complete package
The auto-complete package was developed to automatically complete text using information from different sources: predefined dictionaries, text from current buffer, external programs (GNU Global, etags, ...), etc. Semantic could be also used as source of information.
This package is available in the GNU Emacs's package repository (execute M-x
package-list-packages to get list of available packages), but you can also install it via
el-get or manually. Installation & customization are described in user's manual, so I
won't cover these parts.
To use information from Semantic for names completion, you need to add ac-source-semantic
or ac-source-semantic-raw into ac-sources list (this list allows you to control which data
sources will be used for current buffer, so you can change it as you want).
ac-source-semantic-raw differs from ac-source-semantic that for it the filtering of
information isn't performed.
So your setup can be performed following way — instead of bounding keys for
semantic-ia-complete-symbol-menu, semantic-ia-complete-symbol & other functions, you can
simply add new names completion sources, and after that use auto-complete bindings to get
names completion:
(defun my-c-mode-cedet-hook () (add-to-list 'ac-sources 'ac-source-gtags) (add-to-list 'ac-sources 'ac-source-semantic)) (add-hook 'c-mode-common-hook 'my-c-mode-cedet-hook)
Getting information about tags
The semantic/ia package provides several commands, that allow to get information about
classes, functions & variables (including documentation from Doxygen-style comments).
Currently following commands are implemented:
semantic-ia-show-doc- shows documentation for function or variable, whose names is under point. Documentation is shown in separate buffer. For variables this command shows their declaration, including type of variable, and documentation string (if it's available). For functions, prototype of the function is shown, including documentation for arguments and returning value (if comments are available);
semantic-ia-show-summary- shows documentation for name under point, but information is shown in the mini-buffer, so user will see only variable's declaration or function's prototype;
semantic-ia-describe-class- asks user for a name of the class, and return list of functions & variables, defined in given class, plus all its parent classes.
Navigation in source code
One of the most useful commands for navigation in source code is the semantic-ia-fast-jump
command, that allows to jump to declaration of variable or function, whose name is under
point. You can return back by using the semantic-mrub-switch-tag command (C-x B), that is
available when you enable the semantic-mru-bookmark-mode minor mode.
Semantic also provides two additional commands for jumping to function or variable:
defined in current file —
semantic-complete-jump-local (C-c , j), or defined in current
project —
semantic-complete-jump (C-c , J). Both commands allow to enter name of
function or variable (including local variables inside functions) and jump to given
definition (you can use name completion when entering the name).
The main difference between semantic-ia-fast-jump & semantic-complete-jump commands is
that the first properly handles complex names, like this::that->foo(), while the second,
can find only simple names, like foo.
The semantic-analyze-proto-impl-toggle command allows to switch between function's
declaration and its implementation in languages, that allow to have separate declaration
and implementation of functions. Another useful command is
semantic-decoration-include-visit, that allows to jump to include file, whose name is
under cursor.
Senator provides several commands for navigation in source code. This is senator-next-tag
(C-c , n) and senator-previous-tag (C-c , p) commands, that move cursor to next or
previous tag. There is also the senator-go-to-up-reference command (C-c , u), that moves
cursor to the "parent" tag (for example, for class member function, "parent" tag is class
declaration).
Search for places where function is called
Semantic also has very useful command —
semantic-symref, that allows to find places,
where symbol (whose name is under point) is used in your project. If you want to find use
of symbol with arbitrary name, then you can use the semantic-symref-symbol command, that
allows to enter name of the symbol to lookup.
If references to given name weren't found in corresponding database (GNU Global, etc.),
then these commands will try to find them using the find-grep command. As result of execution
of these commands, a new buffer with results will be created, and user can jump to found
places:
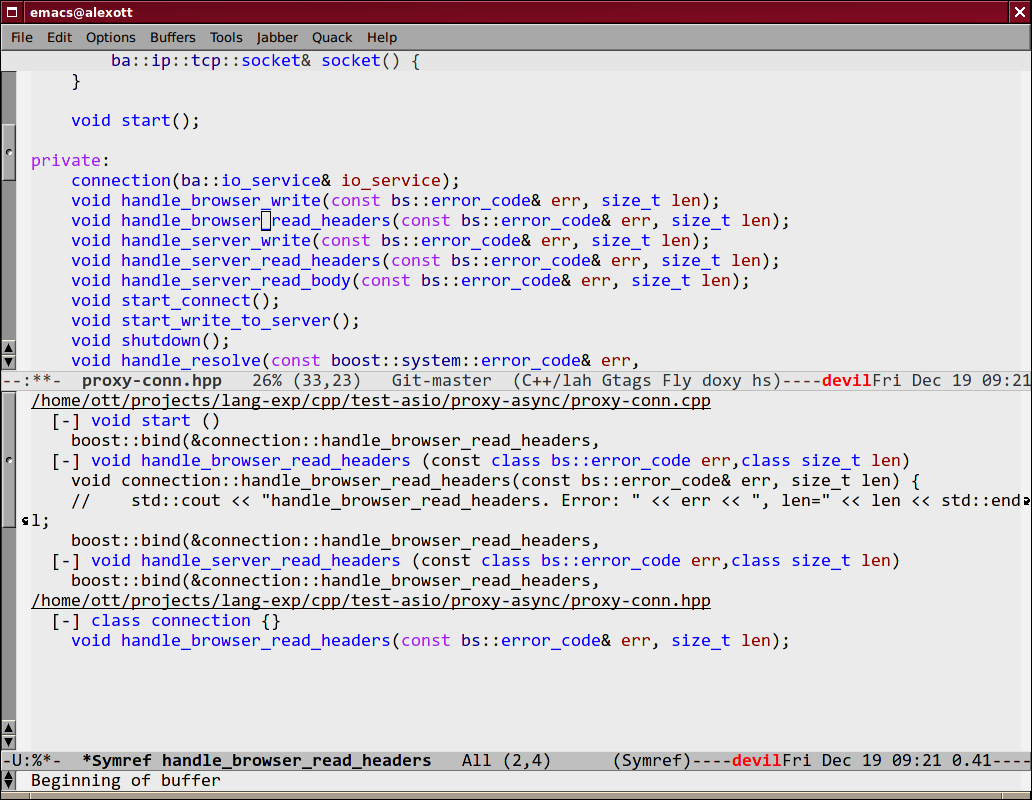
Source code folding
As Semantic has almost complete syntactic information about source code, this allows it to
implement folding functionality, similar to functionality implemented by hideshow package.
To enable this feature, you need to perform customization of the
global-semantic-tag-folding-mode variable. When you'll enable it, this will lead to
displaying of small triangles at the fringle field, and you will able to fold and unfold
pieces of code by clicking on them (this should work not only for source code, but also
for comments, and other objects).
Senator also has similar functionality, but it's usually used for top-level objects —
functions, class declarations, etc. You can fold piece of code with the senator-fold-tag
command (C-c , -), and unfold it with senator-unfold-tag (C-c , +).
More Senator's commands
The Senator package provides number of commands for work with tags, that allow user to cut
or copy tag, and insert it in another place. To cut current tag (usually this is
declaration of some function, or its implementation) the senator-kill-tag command (C-c ,
C-w) should be used. You can insert complete tag with standard key binding C-y, while the
senator-yank-tag command (C-c , C-y) inserts only tag declaration, without body. Another
useful command is senator-copy-tag (C-c , M-w), that copies current tag — this is very
handy when, for example, you want to insert declaration of function into include file.
Senator allows to change behaviour of standard search commands (re-search-forward,
isearch-forward and other), when you work with source code, such way, so they will perform
search only in the given tags. To enable this mode you can use the
senator-isearch-toggle-semantic-mode command(C-c , i), and with the
senator-search-set-tag-class-filter command (C-c , f) you can limit search to given tag
types —
function for functions, variable for variables, etc.
You can also perform tags search without enabling this mode — you just need to call
corresponding command: senator-search-forward or senator-search-backward.
Work with Srecode
The Srecode package allows user to define code templates, but it differs from other
packages, that provide insertion of templates, because list of available templates can
vary depending on the current context. For example, insertion of get/set functions should
happen only when you inside class declaration. Or, insertion of function's declaration,
may happen only outside of other function.
The main command, that is used to insert templates, is the srecode-insert, that is bound
to the C-c / / keys. This command will ask user for template's name (you can enter it
using name completion). List of available templates will vary, depending on the current
context. If you want to insert the same template once again, then you can use the
srecode-insert-again command (C-c / .).
Templates that are defined by user, can also use they own key bindings. They can use
lower-case symbols from range C-c / [a..z], and user can specify in template's definition,
which key will be assigned to it. For example, for C++ you can use the C-c / c key
binding to insert class declaration.
Key bindings, that use upper-case symbols, are reserved for templates & commands defined
in Srecode. For example, C-c / G (srecode-insert-getset) inserts pair of functions
get/set for some class member variable, while C-c / E (srecode-edit) is used to edit
templates. List of these commands isn't constant, so you need to look into documentation
to find actual list of commands.
Besides templates, supplied with CEDET, user can define their own templates, and store
them in the ~/.srecode directory, where CEDET will find them automatically. You can read
about template's creation in the Srecode manual, that comes together with other
documentation in the CEDET distribution.
Additional packages
Together with CEDET the number of additional packages is supplied. Some of them are
located in the contrib subdirectory, that you need to add to library search list.
The eassist package
The eassist package provides several commands, that use information obtained from Semantic. By default, these commands have no predefined key bindings, so you need to select them yourself.
The eassist-list-methods command, executed in the file with source code, will show you a
list of functions, defined in current buffer, and will allow you to perform quick jump to
selected function.
If you develop code in C and/or C++ languages, then the eassist-switch-h-cpp command,
could be very useful to you — it jumps between header file and file, that contains
implementation (if they have same names, but different extensions).
1. You can use following configuration files as a base for your configuration: standalone versions up to 1.1, standalone version after 1.1 release & bundled with GNU Emacs.
2. There is also semantic-complete-analyze-inline command, that shows list of all
possible completions in separate window, that is often handy than graphical menu
3. If name completion works improperly, then try to analyze why this happens, and send bug report only after this. Information about debugging you can find in Semantic User Guide in section Smart Completion Debugging
Last change: 12.03.2014 07:58
Copyright © 1997-2011Alex Ott · Design by Andreas Viklund · 