Меню:
Этот рассказ не претендует на звание полного описания настройки Emacs как среды разработки на разных языках (это будет отдельная статья), а является попыткой написать краткий рассказ о настройке пакета CEDET для работы с языками программирования C & C++, хотя большая часть изложенного подходит и к работе с другими языками, поддерживаемыми пакетом CEDET.
Имейте ввиду, что данная статья описывает автономные версии CEDET вплоть до релиза 1.1. После этого релиза, произошло много изменений, связанных в первую очередь с переходом на новую структуру каталогов и использования того же метода активации CEDET, что используется в GNU Emacs. Я постараюсь обновить статью в ближайшее время, а пока вы можете использовать мой конфигурационный файл в котором уже используется новая схема активации пакетов CEDET.
Что такое CEDET?
Пакет CEDET объединяет в своем составе несколько пакетов, реализующих различную функциональность, но объединенных вокруг одной задачи по работе с исходным кодом на различных языках программирования.
- Semantic — является основой для построения анализаторов для различных языков программирования, позволяя использовать общее представление извлеченной информации для разных языков, используя которую реализуется остальной функционал не только CEDET, но и других пакетов — JDEE и ECB, которые являются попыткой создать среды разработки, близкие по виду к имеющимся на рынке (Eclipse, NetBeans и т.п.);
- SemanticDB — входит в состав Semantic, и реализует интерфейсы к разным модулям хранения информации, используемой при дополнении имен, навигации по коду и т.п. Синтаксическая информация может сохраняться между сессиями работы в Emacs, что уменьшает потребность в регулярном разборе одного и того же кода;
- Senator — реализует функциональность для навигации по синтаксической информации, извлеченной Semantic;
- Srecode — библиотека для генерации кода основываясь на существующей синтаксической информации, в том числе и полученной в результате работы Semantic;
- EDE — реализует набор расширений, которые позволяют работать с проектами — управлять списком целей для сборки, выполнять сборку проекта и т.п. Кроме того, используя концепцию проекта, существует возможность более точного использования Semantic для дополнения имен и другой функциональности;
- Speedbar — используется для отображения информации о текущем буфере, основываясь на данных из различных источниках — Semantic, специализированные провайдеры информации (например, для texinfo & html) и т.п.
- Eieio — реализация CLOS-like (Common Lisp Object System) инфраструктуры для Emacs Lisp;
- Cogre — библиотека для отрисовки UML-подобных диаграм в буфере Emacs с базовой интеграцией с Semantic.
Установка CEDET
Лучше всего в настоящее время пользоваться версией CEDET находящейся в репозитории на Sourceforge.net. После загрузки данных из репозитория, необходимо перейти в нужный каталог и скомпилировать пакет с помощью следующей команды:
emacs -Q -l cedet-build.el -f cedet-build
или, использовать следующую комманду для компиляции пакета в окне терминала и выхода после компиляции:
emacs -Q -nw -l cedet-build.el -f cedet-build -f save-buffers-kill-terminal
Базовая настройка пакета
Загрузка пакета целиком осуществляется с помощью скрипта cedet.el, поэтому добавьте
следующую строку в ваш файл инициализации1:
(load-file "~/emacs/cedet/common/cedet.el")
Если планируете использовать проекты, то необходимо включить соответствующий режим, реализуемый пакетом EDE:
(global-ede-mode t)
Настройка Semantic
В зависимости от того, какие возможности вы хотите получить от Semantic, вы можете воспользоваться одной из команд для загрузки соответствующих наборов функциональности (они перечислены в порядке возрастания реализованных функций, и каждый следующий включает в себя предыдущие наборы функциональности):
semantic-load-enable-minimum-features— включает только необходимый минимум возможностей — поддержание актуальности синтаксической информации для текущего буфера, сохранение синтаксической информации для последующего использования (Semanticdb) и подгрузку существующей информации Semanticdb и Ebrowse;semantic-load-enable-code-helpers— включаетsenator-minor-modeдля навигации по буферу,semantic-mru-bookmark-modeдля запоминания и навигации между тагами, иsemantic-idle-summary-mode, который показывает информацию для тага под курсором;semantic-load-enable-gaudy-code-helpers— включаетsemantic-stickyfunc-nameдля отображения имени текущей функции в самой верхней строке буфера,semantic-decoration-modeдля декорирования тагов, используя различные аттрибуты, иsemantic-idle-completion-modeдля генерации списка возможных дополнений имен, если пользователь останавливает свою работу на некоторое время;semantic-load-enable-excessive-code-helpers— подключаетwhich-func-mode, который отображает имя текущей функции в строке состояния;semantic-load-enable-semantic-debugging-helpers— включает несколько режимов, которые полезны при отладке Semantic — показ ошибок разбора кода, состояния парсера и т.п.
Таким образом, вам необходимо поместить вызов одной из функций в файл инициализации после загрузки CEDET. Например, вот так
(semantic-load-enable-excessive-code-helpers)
Чтобы использовать возможности по дополнению имен и показу информации о функциях и
классах, вам необходимо загрузить пакет semantic-ia с помощью следующей команды:
(require 'semantic-ia)
После загрузки этого пакета, вы получите возможность использования соответствующего функционала, описанного ниже.
Системные подключаемые файлы
Для полноценной работы с системными библиотеками, Semantic должен иметь информацию о подключаемых файлах, которые содержат информацию о функциях и типах данных, предоставляемых этими библиотеками.
Если вы используете GCC для программирования на C & C++, то пакет может автоматически
получить данные о нахождении системных подключаемых файлов. Для этого вам нужно загрузить
пакет semantic-gcc с помощью следующей команды:
(require 'semantic-gcc)
Вы также можете явно задать дополнительные пути поиска подключаемых файлов, которые будут
использоваться при работе в определенном режиме. Для этого используется команда
semantic-add-system-include, которой передается два параметра — путь к заголовочным
файлам, и имя режима в котором этот путь будет использоваться. Например:
(semantic-add-system-include "~/exp/include/boost_1_37" 'c++-mode)
Оптимизация работы Semantic
Для оптимизации поиска тагов вы можете использовать несколько приемов:
- Ограничить область поиска путем настройки проекта EDE, как это описано ниже;
- Явно указать список корневых каталогов для ваших проектов, так что Semantic будет использовать ограниченное количество баз тагов;
- Заранее сгенерировать базы данных тагов для часто используемых каталогов (
/usr/include,/usr/local/include, и т.п.) с помощью командsemanticdb-create-ebrowse-databaseилиsemanticdb-create-cscope-database; - Ограничить диапазон поиска с помощью настройки переменной
semanticdb-find-default-throttleдля конкретных режимов, например, не использовать информацию о системных подключаемых файлов, убрав директивуsystemиз списка объектов поиска для режимаc-mode:
(setq-mode-local c-mode semanticdb-find-default-throttle
'(project unloaded system recursive))
Кроме того, вы можете указать Semantic, что он должен извлекать синтаксическую информацию
из текущего буфера только тогда, когда Emacs ничего не делает. Для этого вам необходимо
включить semantic-idle-scheduler-mode, а для настройки времени ожидания (в секундах)
используется переменная semantic-idle-scheduler-idle-time.
Интеграция с imenu
Пакет Semantic умеет интегрироваться с пакетом imenu, который позволяет отображать меню со списком функций, переменных и т.п. информацией. Для включения этой поддержки, вам необходимо добавить следующий код в файл инициализации:
(defun my-semantic-hook () (imenu-add-to-menubar "TAGS")) (add-hook 'semantic-init-hooks 'my-semantic-hook)
Настройка Semanticdb
Если вы использовали стандартный механизм загрузки компонентов CEDET, то Semanticdb будет загружен автоматически. Иначе, вы можете загрузить и включить его с помощью следующих команд:
(require 'semanticdb) (global-semanticdb-minor-mode 1)
Для настройки поведения Semanticdb используется некоторое количество переменных, которые
позволяет указать вам куда сохранять данные, а также другие параметры. Эти переменные
можно настроить через группу настройки semanticdb.
Кроме того, Semanticdb может использовать базы данных, сгенерированные внешними утилитами
—
gtags из состава GNU Global, ctags, ebrowse & cscope. Для активации этой поддержки, вы
можете использовать следующий код:
;; если вы хотите включить поддержку gnu global (when (cedet-gnu-global-version-check t) (require 'semanticdb-global) (semanticdb-enable-gnu-global-databases 'c-mode) (semanticdb-enable-gnu-global-databases 'c++-mode)) ;; включить поддержку ctags для основных языков: ;; Unix Shell, Perl, Pascal, Tcl, Fortran, Asm (when (cedet-ectag-version-check) (semantic-load-enable-primary-exuberent-ctags-support))
Настройка Semantic для работы с проектами на C & C++
Для правильной работы Semantic с кодом на С & C++ рекомендуется воспользоваться пакетом
EDE (работа с проектами и т.п.) также из поставки CEDET. Для этих языков, EDE определяет
специальный тип проекта —
ede-cpp-root-project, который предоставляет Semantic
дополнительную информацию, используемую для анализа исходных текстов вашего проекта, и
последующего использования информации только для вашего проекта. Для этого, необходимо
включить соответствующий режим при загрузке пакета.
Для определения проекта используется следующий код:
(ede-cpp-root-project "Test" :name "Test Project" :file "~/work/project/CMakeLists.txt" :include-path '("/" "/Common" "/Interfaces" "/Libs" ) :system-include-path '("~/exp/include") :spp-table '(("isUnix" . "") ("BOOST_TEST_DYN_LINK" . "")))
В качестве параметра :file вам надо указать любой из файлов, находящихся в корневом
каталоге проекта. Этот файл никак не анализируется, а служит только отправной точкой для
поиска файлов.
Для поиска подключаемых файлов используется каталоги из двух списков, которые могут быть
определены в проекте. Параметр :system-include-path используется для задания списка
полных путей каталогов, в которых будет производиться поиск "системных" подключаемых
файлов. А параметр :include-path задает список каталогов, относительно корневого каталога
проекта, в которых будет производиться поиск подключаемых файлов, специфичных для вашего
проекта (заметьте, что имена начинаются со знака /, что означает, что имена задаются
относительно корневого каталога проекта). Вместо явного задания каталогов, вы также
можете задать функцию, которая будет заниматься поиском файлов вашего проекта. Об этом вы
можете прочитать в руководстве EDE.
Еще один параметр, который может быть задан в проекте — список определений, которые будут
использоваться при обработке кода препроцессором. Параметр :spp-table позволяет
определить список пар, состоящих из имени символа и связанного с ним значения. В нашем
примере мы определяем два символа isUnix и BOOST_TEST_DYN_LINK, которые будут переданы
препроцессору, что позволит произвести правильный разбор кода.
В том случае, если это необходимо, пользователь может переопределить для проекта некоторые
переменные путем указания параметра :local-variables, указав набор пар вида имя
символа/значение, и эти значения будут установлены для файлов, входящих в проект.
Обработка кода препроцессором
Более подробно про определения символов препроцессора вы можете прочитать в документации
на переменную semantic-lex-c-preprocessor-symbol-map, а список символов препроцессора,
определенных для какого-то файла, можно получить с помощью команды
semantic-lex-spp-describe, и использовать нужные значения для настройки проекта.
Многие библиотеки перечисляют все используемые макросы в одном заголовочном файле, и
поэтому вы можете воспользоваться существующими определениями. Для этого, вы должны
указать необходимые файлы в переменной semantic-lex-c-preprocessor-symbol-file, и при
проведении анализа, значения из этих файлов будут автоматически учтены. По умолчанию, эта
переменная содержит только одно значение — файл с определениями для стандартной
библиотеки C++. В качестве примера я хочу привести настройку CEDET для работы с
библиотекой Qt4:
(setq qt4-base-dir "/usr/include/qt4") (semantic-add-system-include qt4-base-dir 'c++-mode) (add-to-list 'auto-mode-alist (cons qt4-base-dir 'c++-mode)) (add-to-list 'semantic-lex-c-preprocessor-symbol-file (concat qt4-base-dir "/Qt/qconfig.h")) (add-to-list 'semantic-lex-c-preprocessor-symbol-file (concat qt4-base-dir "/Qt/qconfig-dist.h")) (add-to-list 'semantic-lex-c-preprocessor-symbol-file (concat qt4-base-dir "/Qt/qglobal.h"))
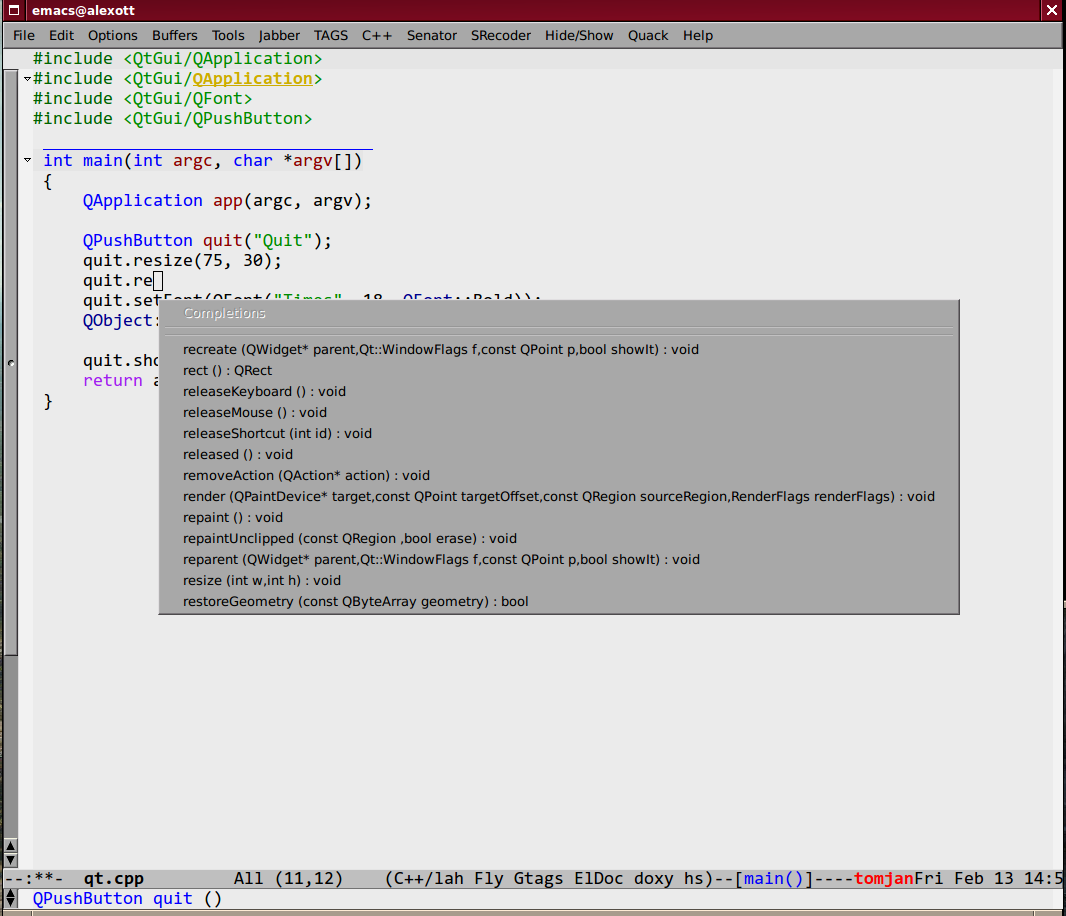
После добавления этого кода в ваш файл инициализации, вы сможете использовать механизмы дополнения для классов, определенных в Qt4. Пример дополнения вы можете увидеть на рисунке ниже.
Использование Semantic
С точки зрения пользователя Semantic реализует несколько основных функции — дополнение
имен, получение информации о тагах (переменных, функциях и т.д.) и навигацию по исходному
коду. Часть команд реализуется пакетом semantic-ia, часть пакетом Senator, и часть —
ядром самого Semantic.
Часть команд не имеет стандартных привязок клавиш, поэтому вам лучше самим выбрать удобные для вас привязки и привязать к ним нужные команды, например вот так:
(defun my-cedet-hook () (local-set-key [(control return)] 'semantic-ia-complete-symbol) (local-set-key "\C-c?" 'semantic-ia-complete-symbol-menu) (local-set-key "\C-c>" 'semantic-complete-analyze-inline) (local-set-key "\C-cp" 'semantic-analyze-proto-impl-toggle)) (add-hook 'c-mode-common-hook 'my-cedet-hook)
Я хотел бы отметить, что работа над Semantic ведется достаточно активно, и в случае неправильной работы каких-либо компонент, просьба отправлять примеры кода в список рассылки cedet-devel — автор реагирует на баг-репорты достаточно оперативно.
Дополнение имен
Дополнение имен функций и классов — достаточно востребованная и часто используемая
функция2. В составе Semantic идет два пакета реализующих данную функциональность —
semantic-ia и Senator. Функции реализованные в составе semantic-ia используют для
определения списка возможных дополнений функцию semantic-analyze-possible-completions,
которая учитывает достаточно много параметров — области видимости определений, и т.п., и
кроме того, она может быть переопределена пользователем для более точной генерации списка
имен. В то время как функции Senator используют более простой механизм определения списка
возможных дополнений (в основном используя информацию об определениях в текущем файле),
что иногда ведет к неправильному его формированию, хотя и работает намного быстрее чем
функции semantic-ia.
Использование функции semantic-ia-complete-symbol при наборе кода приведет к дополнению
соответствующего имени — функции, переменной или переменной-члена класса, в зависимости
от контекста в котором она была вызвана. Если существует несколько вариантов, то имя
будет дополнено до наибольшей общей части имени, а при повторном вызове команды, будет
показан буфер со списком всех возможных вариантов имени. Пользователь может также
воспользоваться функцией semantic-ia-complete-symbol-menu, которая также анализирует
контекст в котором она вызвана, и отображает варианты дополнений в виде графического меню,
перемещаясь по которому пользователь может выбрать нужный вариант дополнения3. Кроме
того, существует функция semantic-ia-complete-tip, которая отображает список возможных
дополнений в виде всплывающей подсказки (tooltip).
Как упоминалось выше, Senator также предоставляет функции для дополнения имен, которые
работают более быстро, но учитывают меньше параметров при генерации списка дополнений.
Функция senator-complete-symbol (C-c , TAB) дополняет имя для текущего тага, при этом она
сразу подставляет имя первого варианта из списка всех возможных вариантов. Если вам это
не подходит, то вы можете продолжать вызывать эту функцию для перебора всех вариантов
дополнения имен (что не всегда удобно). В том случае, если вариантов имен много, или вы
хотите посмотреть полный список функций и переменных для какого-то класса, то лучше
воспользоваться функцией senator-completion-menu-popup (C-c , SPC), которая отображает
список возможных вариантов дополнений в виде графического меню.
Помимо этого, для отдельных языков пользователь может включить специальный режим —
semantic-idle-completions-mode (или воспользоваться функцией
global-semantic-idle-scheduler-mode чтобы включить его для всех режимов) при котором
дополнения имен начинают показываться спустя некоторое время бездействия. При этом, в
качестве варианта предлагается первое значение из списка возможных дополнений, и
пользователь может использовать клавишу TAB для перебора вариантов.
Для языков с C-подобным синтаксисом, пользователь может воспользоваться командой
semantic-complete-self-insert, привязанной к клавишам . и >, как это показано ниже:
(defun my-c-mode-cedet-hook () (local-set-key "." 'semantic-complete-self-insert) (local-set-key ">" 'semantic-complete-self-insert)) (add-hook 'c-mode-common-hook 'my-c-mode-cedet-hook)
Использование этого кода приведет к тому, что при нажатии . или > после переменных,
экземпляров класса, будет показан список возможных дополнений для данного класса.
Получение информации о тагах
Пакет semantic-ia реализует несколько команд, которые позволяют разработчику получать
информацию о классах, функциях и переменных. В качестве документации используются
комментарии, извлеченные из исходного кода, в том числе и используемые для генерации
документации с помощью Doxygen. В настоящее время реализованы следующие функции:
semantic-ia-show-doc- показывает документацию для функции или переменной чье имя находится под курсором. Документация показывается в отдельном буфере. Для переменных показывается их объявление, включающее тип, и строка документации, если она есть. Для функций показывается их прототип, и документация по аргументам функции и возвращаемому значению;
semantic-ia-show-summary- показывает документацию для символа под курсором, но при информация отображается в мини-буфере, так что пользователь увидит только объявление переменной или функции;
semantic-ia-describe-class- запрашивает у пользователя имя класса и возвращает список функций и переменных определенных в данном классе и всех родительских классах.
Навигация по коду
Одной из самых полезных функций для навигации является функция semantic-ia-fast-jump,
которая позволяет переходить к объявлению переменной или функции, чье имя находится под
курсором. Вернуться назад вы сможете использовав функцию semantic-mrub-switch-tag (C-x
B), которая доступна при использовании semantic-mru-bookmark-mode.
Также в Semantic определено две функции для перехода к объявлению функции или переменной
находящемся в текущем файле —
semantic-complete-jump-local (C-c , j), или в области
видимости всего проекта —
semantic-complete-jump (C-c , J). Обе эти функции позволяют
ввести имя функции или переменной (включая локальные для функций), используя механизмы
дополнения имен, и перейти к данному определению.
Функция semantic-analyze-proto-impl-toggle позволяет "прыгать" между объявлением функции и
ее реализацией для языков, поддерживающих раздельное объявление и реализацию. Еще одной
полезной функцией является semantic-decoration-include-visit, которая позволяет
переключиться в заголовочный файл, чье имя находится под курсором.
Senator также реализует несколько функций для навигации в исходном коде. Сюда относятся
функции senator-next-tag (C-c , n) и senator-previous-tag (C-c , p), которые перемещаются
к следующему или предыдущему тагу, а также функция senator-go-to-up-reference (C-c , u),
которая переходит к "родительскому" тагу (например, для функции-члена класса,
"родительским" тагом будет объявление класса).
Поиск использования функции
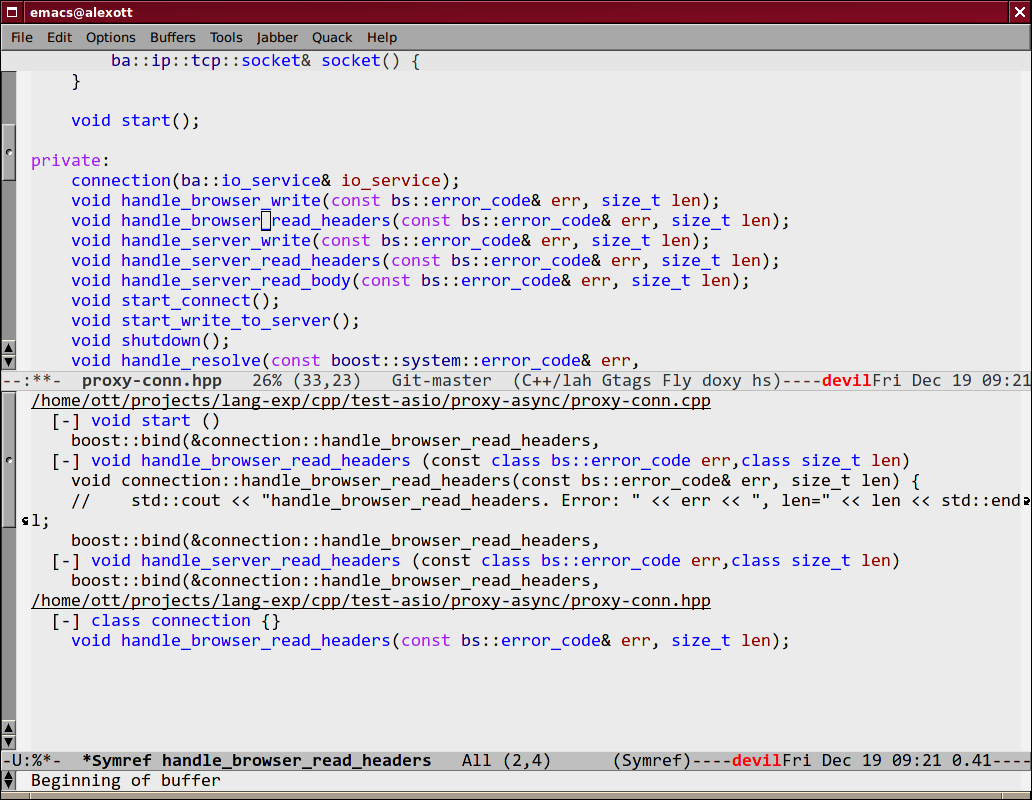
Недавно в Semantic была добавлена полезная команда —
semantic-symref, которая позволяет
найти где символ, чье имя находится под курсором, используется в проекте. В том случае,
если вы хотите найти данные для символа с произвольным именем, то вам стоит
воспользоваться функцией semantic-symref-symbol, которая позволяет вам ввести имя символа
вручную.
При этом, если вхождения символа в соответствующей базе данных (GNU Global и т.п.) не
найдены, то команда попытается найти использование заданного символа с помощью команды
find-grep. В итоге создается вот такой вот буфер с найдеными результатами, используя
который пользователь может перемещаться к нужным частям кода:
Свертывание (folding) кода
Поскольку Semantic имеет практически полную синтаксическую информацию об исходных текстах,
то это позволяет реализовать практически такую же функциональность по свертыванию кусков
кода, которая реализуется пакетом hideshow. Для получения этой функциональности вам
необходимо выполнить настройку переменной global-semantic-tag-folding-mode. Это приведет
к появлению небольших треугольников в области значков (fringle), нажимая на которые можно
сворачивать или разворачивать соответствующий кусок текста (не только исходного текста, но
и комментариев и других объектов).
В Senator также имеется схожая функциональность, но она в основном предназначена для
работы с объектами верхнего уровня — функциями, классами и т.п. Сворачивание участка
кода производится с помощью функции senator-fold-tag (C-c , -), а разворачивание с помощью
функции senator-unfold-tag (C-c , +).
Прочие команды Senator
Пакет Senator определяет некоторое количество команд для работы с тагами — вырезать или
скопировать текущий таг, вставить его в другом месте, и т.д. Для вырезания текущего тага
(обычно это определение функции) определена функция senator-kill-tag (C-c , C-w).
Вставить таг целиком в другом месте можно с помощью стандартной комбинации клавиш C-y, в
то время как функция senator-yank-tag (C-c , C-y) вставляет лишь определение данного тага,
без тела. Еще одной полезной функцией является senator-copy-tag (C-c , M-w), которая
копирует текущий таг для последующей вставки (с помощью C-c , C-y), что очень удобно для
вставки объявлений функций в заголовочных файлах, а полный текст скопированного тага,
вставляется с помощью C-y.
Senator позволяет изменить поведение стандартных функций поиска (re-search-forward,
isearch-forward и др.) при работе с исходным кодом таким образом, что функции будут
производить поиск только в соответствующих тагах. Чтобы включить этот режим вы можете
использовать функцию senator-isearch-toggle-semantic-mode (C-c , i), а с помощью функции
senator-search-set-tag-class-filter (C-c , f) вы можете ограничить пространство поиска
только указанными классами тагов —
function для функций, variable для переменных, и т.д.
Вы также можете воспользоваться поиском по тагам не переключаясь явно в режим ограничения
поиска. Вам нужно лишь вызвать одну из функций: senator-search-forward или
senator-search-backward.
Работа с Srecode
Пакет Srecode позволяет пользователю определять различные шаблоны, но в отличии от других
систем для работы с шаблонами, вставка новых кусков текста, может сильно зависеть от
текущего контекста, например, вставка пары get/set может производиться только внутри
объявления класса, или вставка объявления новой функции может производиться только вне
какой-либо другой функции.
Основной командой, используемой для вставки шаблонов, является функция srecode-insert,
которая привязана к сочетанию клавиш C-c / /. Эта функция запросит у вас имя шаблона,
которое вы можете ввести, используя механизмы дополнения. В зависимости от текущего
контекста, список доступных шаблонов может меняться. Если вы хотите вставить тот же самый
шаблон еще раз, то в можете воспользоваться командой srecode-insert-again (C-c / .),
которая вставит последний использованный шаблон.
Шаблоны также могут определять собственные привязки клавиш — для них зарегистрирован
диапазон сочетаний C-c / [a..z], и пользователь может указать в шаблоне какая клавиша
будет к нему привязана — например, для C++ использование сочетания C-c / c приведет к
вставке шаблона для класса.
Сочетания клавиш, использующие заглавные буквы, зарезервированы для шаблонов и команд,
определенных в Srecode. Например, C-c / G (srecode-insert-getset) вставляет пару функций
get/set для заданной переменной-члена класса, а C-c / E (srecode-edit) используется для
редактирования шаблонов. Число этих команд регулярно меняется, поэтому для получения
полного их списка, лучше посмотреть в документацию.
Кроме шаблонов поставляемых вместе с CEDET, пользователь может определять собственные
шаблоны и сохранять их в каталоге ~/.srecode, где CEDET найдет их автоматически. Про
создание шаблонов вы можете прочитать в руководстве для данного пакета, которое входит в
состав документации, поставляемой вместе с CEDET.
Дополнительные пакеты
Вместе с CEDET поставляется некоторое количество дополнительных пакетов, часто находящихся
в каталоге contrib дистрибутива, который автоматически добавляется в пути поиска пакетов,
поэтому загрузка нужных пакетов производится без дополнительных действий.
Пакет eassist
Пакет eassist реализует несколько дополнительных команд, которые в своей работе используют информацию, полученную от Semantic. По умолчанию эти команды не имеют предопределенных привязок клавиш, поэтому вам необходимо самим назначить нужные клавиши, если вы планируте пользоваться этими командами.
Функция eassist-list-methods, запущенная в файле с исходным кодом, показывает список
функций в этом файле, позволяя выполнить быстрый переход к выбранной функции.
При разработке на языках C и C++ полезной может оказаться функция eassist-switch-h-cpp,
которая выполняет переключение между подключаемым файлом и файлом реализации (если они
имеют одинаковые имена, но разные расширения файлов).
1. D моеv репозитории с конфигурацией Emacs вы можете найти мой файл инициализации CEDET который можно использовать в качестве основы для дальнейшей работы (хотя там достаточно много лишнего).
2. Существует также функция semantic-complete-analyze-inline, которая отображает список
возможных дополнений в отдельном окне, часто более удобно чем использование
графического меню.
3. В том случае, если дополнение имен работает неправильно, то попробуйте проанализировать почему это происходит, и лишь затем отправлять сообщение об ошибке в список рассылки. Описание процесса отладки вы можете найти в Semantic User Guide в разделе Smart Completion Debugging.
Last change: 05.03.2013 16:54
Copyright © 1997-2011Alex Ott · Design by Andreas Viklund · 